Lebanese SaaS products targeting Gulf markets add 100-200ms of latency from eu-west-1 to Riyadh or Dubai. Multi-region is not just a latency optimization. It is the difference between feeling local and feeling like a slow international product. This is how we deploy RTYLR across MENA.
The Latency Problem for Lebanese SaaS in the Gulf
Lebanese SaaS products targeting Gulf markets add 100-200ms of round-trip latency when served from eu-west-1 (Ireland). For a restaurant POS like RTYLR serving operators in Riyadh or Dubai, that latency is noticeable. API calls that feel instant in Beirut feel sluggish in the Gulf.
Multi-region deployment is not just a latency optimization. It is the difference between feeling like a local product and feeling like a slow international one. Gulf operators have local alternatives. Latency is a retention problem.
This post covers the architecture we use for multi-region AWS deployments, including region selection, routing, ECS Fargate setup, database strategy, and the cost profile for an early-stage SaaS.
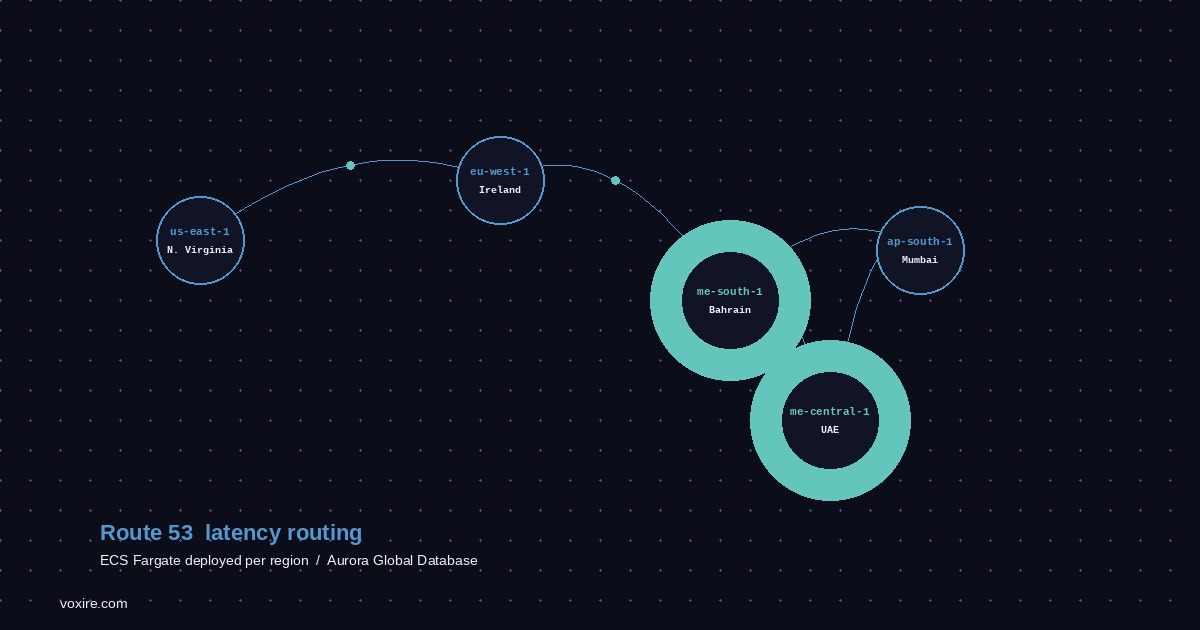
AWS Region Selection for MENA Coverage
AWS has two dedicated MENA regions:
| Region | Location | Typical RTT from Riyadh | Typical RTT from Dubai | |---|---|---|---| | me-south-1 | Bahrain | ~20ms | ~30ms | | me-central-1 | UAE | ~40ms | ~5ms | | eu-west-1 | Ireland | ~130ms | ~120ms |
For most MENA SaaS products, the practical choice is:
- me-south-1 (Bahrain) as the primary MENA region. It covers Saudi Arabia, Kuwait, Bahrain well. It has been available longer and has broader service support.
- me-central-1 (UAE) if you have significant UAE-specific traffic or data residency requirements. Some enterprise customers in UAE require data to stay in UAE.
- eu-west-1 (Ireland) as the origin region, where the primary database write endpoint lives, and as a fallback.
For RTYLR, we use me-south-1 and eu-west-1. The UAE region came later and we have not migrated to it yet, but me-south-1 already cuts Gulf latency from ~150ms to ~25ms.
Note that not all AWS services are available in MENA regions. Before committing to a region, verify that the services you need (ElastiCache, SES, etc.) are available in me-south-1 and me-central-1. The list changes frequently.
Route 53 Latency-Based Routing
Route 53 latency-based routing is the simplest way to send users to the nearest region. Each region gets a latency record pointing to its regional ALB. Route 53 measures latency from each AWS edge location to each region and routes the DNS query accordingly.
Key configuration decisions:
Health checks: Every latency record must have a Route 53 health check. If the regional ALB is unhealthy, Route 53 stops routing to it and falls back to the next best latency record. Without health checks, Route 53 routes to a dead region and your users see errors.
TTL: Set the TTL on latency records to 60 seconds. Lower TTLs mean faster failover but more Route 53 queries. Higher TTLs mean slower failover. 60 seconds is a reasonable starting point for a SaaS product.
Failover vs latency: You can combine latency-based routing with failover routing. The primary record in each region uses latency-based routing. A secondary record in eu-west-1 uses failover routing and activates when the primary is unhealthy. This gives you regional latency benefits with a global fallback.
Route53:
voxire.com -> latency record -> me-south-1 ALB (primary)
voxire.com -> latency record -> eu-west-1 ALB (primary)
voxire.com -> failover record -> eu-west-1 ALB (secondary, always on)
ECS Fargate Per-Region Deployment
The application runs on ECS Fargate. Each region has an independent ECS cluster with the same task definitions. The same container image runs in both regions. There is no region-specific code.
The Terraform structure uses a module per region:
module "app_eu_west_1" {
source = "./modules/ecs_app"
region = "eu-west-1"
cluster_name = "rtylr-prod-eu"
task_definition = aws_ecs_task_definition.app.arn
subnets = module.vpc_eu.private_subnets
alb_arn = module.alb_eu.arn
desired_count = 2
}
module "app_me_south_1" {
source = "./modules/ecs_app"
region = "me-south-1"
cluster_name = "rtylr-prod-me"
task_definition = aws_ecs_task_definition.app.arn
subnets = module.vpc_me.private_subnets
alb_arn = module.alb_me.arn
desired_count = 2
}
Deployments update both regions. We use a blue-green deployment strategy at the ECS service level, updating eu-west-1 first, verifying health, then updating me-south-1. This is handled by the CI pipeline, not by AWS CodeDeploy, because we need more control over the rollout sequence.
Key decisions for ECS multi-region:
- Same task definition ARN: task definitions are global in AWS. Both regions reference the same task definition revision. This ensures identical container configuration across regions.
- Separate ALBs: each region has its own Application Load Balancer. The ALB DNS name is the target for the Route 53 latency record.
- Separate VPCs with private subnets: tasks run in private subnets. Outbound internet access goes through a NAT Gateway. Do not put ECS tasks in public subnets.
Database Strategy for Multi-Region
The database is the hardest part of multi-region. ECS tasks are stateless and easy to replicate. The database has state and consistency requirements.
We use Aurora PostgreSQL with Aurora Global Database.
Aurora Global Database gives you:
- A primary writer cluster in one region (eu-west-1 for us)
- Read replicas in other regions (me-south-1)
- Replication lag typically under 1 second
- Automated failover: if the primary writer fails, a regional replica can be promoted to writer in under a minute
Read-heavy queries go to the regional read replica. This covers the majority of RTYLR's traffic: menu reads, order status checks, tenant configuration lookups. Write operations go to the primary writer in eu-west-1 regardless of which region the request arrives in.
The application has two database connection strings:
DB_READ_URL: points to the regional Aurora reader endpointDB_WRITE_URL: points to the global writer endpoint in eu-west-1
type DBPool struct {
reader *pgxpool.Pool
writer *pgxpool.Pool
}
func (p *DBPool) Read() *pgxpool.Pool { return p.reader }
func (p *DBPool) Write() *pgxpool.Pool { return p.writer }
Write latency from me-south-1 to eu-west-1 adds ~130ms per write operation. For RTYLR, most writes are order creation and status updates. The extra latency on writes is acceptable. If you have write-heavy workloads, you need a different strategy (per-region writers with conflict resolution, which is significantly more complex).
Cross-Region Secrets and Configuration
AWS SSM Parameter Store is regional. Each region has its own copy of secrets and configuration. This is the correct approach. Do not share a single SSM path across regions using cross-region reads at runtime.
At startup, the application reads its configuration from the regional SSM Parameter Store:
func loadConfig(ctx context.Context, region string) (*Config, error) {
cfg, err := config.LoadDefaultConfig(ctx,
config.WithRegion(region),
)
if err != nil {
return nil, err
}
ssmClient := ssm.NewFromConfig(cfg)
// fetch parameters by path prefix
return fetchParams(ctx, ssmClient, "/rtylr/prod/")
}
Secrets are populated in each region's SSM as part of the Terraform deployment. The values are the same (same database passwords, same API keys), but they live in the regional SSM namespace.
Never build secrets into the container image. Never pass secrets as environment variables in the ECS task definition (they appear in CloudTrail and the ECS console). Always pull from SSM at startup.
Cost Implications
A common concern with multi-region is cost. For early-stage SaaS, the incremental cost is manageable.
Rough monthly cost breakdown for a two-region setup (eu-west-1 + me-south-1):
| Component | Monthly Cost (est.) | |---|---| | ECS Fargate (2 tasks x 2 regions, 0.5 vCPU, 1GB) | ~$60 | | ALB x 2 regions | ~$40 | | Aurora Global Database (db.r6g.large, 1 writer + 1 reader) | ~$180 | | NAT Gateway x 2 regions | ~$70 | | Route 53 latency records + health checks | ~$10 | | Total | ~$360 |
This is not a precise quote. Costs vary based on traffic volume, data transfer between regions, and Aurora storage. But for a product with moderate traffic, staying under $400/month for two-region coverage is achievable.
Data transfer between regions costs money. Keep cross-region traffic minimal. Do not stream large payloads from eu-west-1 to me-south-1 on every request. The read replica should handle the majority of reads locally.
Observability Across Regions
CloudWatch is regional. Each region produces its own metrics, logs, and alarms independently. Viewing both regions requires switching console regions or building an aggregated view.
For a minimal aggregated observability setup:
- Create a CloudWatch dashboard in eu-west-1 with cross-region widgets pulling metrics from me-south-1
- Set up identical alarms in both regions for p99 latency, error rate, and ECS task health
- Route all alarms to the same SNS topic (one per region), which forwards to PagerDuty or Slack
For application logs, use CloudWatch Logs Insights in each region separately. We have not consolidated logs across regions into a single store (Elasticsearch, Datadog). The cost and complexity are not justified at RTYLR's current scale.
The most useful cross-region metric to track: the replication lag on the Aurora Global Database reader. If it climbs above 5 seconds, reads from the Gulf are serving stale data. Alert on it.
CloudWatch metric: aws/rds AuroraGlobalDBReplicationLag
Threshold: > 5000ms for 3 consecutive minutes
Key Lessons from the First Multi-Region Deployment
- Test failover before you need it. Force the primary region unhealthy in a staging environment and verify that Route 53 routes correctly and the application functions with the remaining region. DNS failover is not instant (60-second TTL means up to 60 seconds of exposure). Know this going in.
- Read replicas lag under write bursts. Aurora Global replication is fast but not zero. During a large write burst (end-of-day batch processing), replica lag can spike to several seconds. Design reads to tolerate slightly stale data or route them to the writer when freshness matters.
- me-south-1 has fewer available services than eu-west-1. We hit this with ElastiCache when setting up the Gulf region. Verify service availability before your architecture depends on it.
- NAT Gateway costs surprise people. NAT Gateway charges per GB of data processed. High-volume logging or frequent large API calls route through it. Monitor NAT Gateway data costs separately.
- Deploy both regions atomically. A deployment that updates eu-west-1 but not me-south-1 leaves your regions running different application versions. Your CI pipeline must treat a multi-region deployment as a single atomic operation with coordinated rollback.
Not sure where to start?
If you are scaling a MENA SaaS product and need multi-region infrastructure that is production-ready and cost-efficient, Voxire can help you design and deploy it. We have done this for RTYLR and can apply the same patterns to your stack. Get in touch at https://voxire.com/get-a-quote/
Enjoying this article?
Enter your email and get a clean, formatted PDF of this article - free, no spam.


